
WAN 2.2-Animate 技术原理解析
作者:XD / 发表: 2025年10月30日 22:23 / 更新: 2025年10月30日 22:29 / 科研学习 / 阅读量:2036
WAN 2.2-Animate(通义万相 2.2-Animate) 是由阿里巴巴通义实验室开发的开源角色动画生成模型(https://arxiv.org/pdf/2509.14055)。 它能够将一张静态角色图像与一段参考视频结合,生成高逼真度的角色动画视频。
模型支持两种核心工作模式:
- Animation(动画)模式:将参考视频中的动作与表情迁移到静态图像上,生成新的动画;
- Replacement(替换)模式:用静态图像角色替换视频原角色,保持光照和色调一致。
这样的设计使动作与角色身份相分离,大幅提高了动画生成的灵活性与真实感。
视频展示了 Animation 与 Replacement 两种模式。模型能精准复刻动作与表情,并保持角色外观一致。
模型架构设计
WAN 2.2-Animate 基于 Wan 系列视频生成模型改进而来。 其底层使用 Wan-I2V(Image-to-Video)扩散模型,一种基于 Diffusion Transformer 的视频生成主干。
在此基础上,引入多模块分层架构,实现参考条件的细粒度控制。
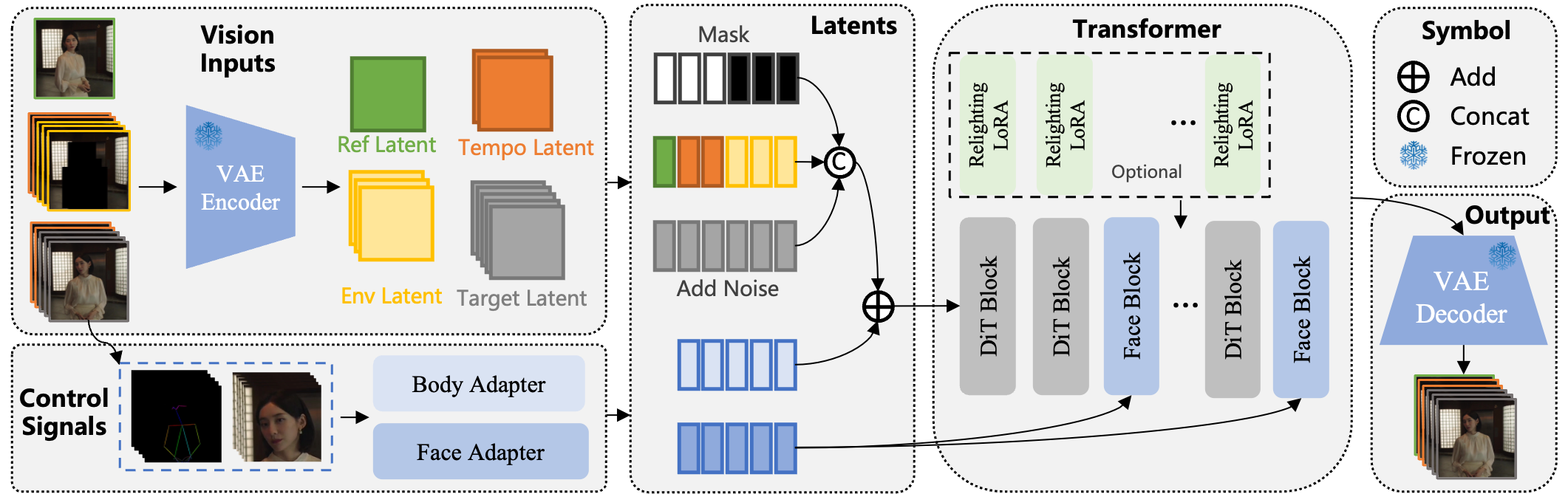
主要模块包括:
- 骨骼关键点注入:驱动肢体动作;
- Face Adapter + Face Block:处理人脸表情;
- Relighting LoRA:在替换模式中调整光照与色调,实现环境融合。
条件输入范式与多条件注入
WAN 2.2-Animate 使用统一的条件输入范式:
- 利用二值掩码(mask)区分“参考帧”和“生成帧”;
- 在 Animation 模式中,仅首帧为参考;
- 在 Replacement 模式中,引入背景帧作为条件。
这种设计可在相同模型中自由切换任务类型,保持兼容 Wan-I2V 结构。
参考图像会被编码为“参考潜码”,与扩散噪声潜码拼接,使视频在整个生成过程中保持人物身份一致。
骨骼驱动的身体动作控制
模型采用基于 人体骨骼关键点 的动作表示。 通过提取姿态(如使用 OpenPose),并将其空间对齐后注入扩散模型噪声层,从而实现精准的动作控制。 这种方法具备良好的泛化性,适用于多种角色类型与风格。
面部表情控制与表达复刻
为实现高保真表情复刻,模型引入:
- Face Adapter:提取参考视频中人脸特征并解耦身份与表情;
- Face Block:在 Transformer 中通过交叉注意力融合表情信号。
通过骨骼信号与人脸信号的解耦注入,模型可同时精确控制动作与表情。
Relighting LoRA 模块
Relighting LoRA(重光 LoRA) 用于替换模式下的光照匹配。 LoRA 以低秩微调的形式,仅作用于自注意力层和交叉注意力层。 其作用是使生成角色的光照、阴影、色调与视频环境相协调,从而实现自然融合。
视频驱动动画的原理与优势
WAN 2.2-Animate 采用 参考视频驱动生成 的方式,让静态角色“活起来”。 核心流程:
- 从视频中提取动作与表情控制信号;
- 由扩散模型将其映射到静态图像角色;
- 生成连续视频序列。
主要优势:
- 动作与身份分离:任意角色可复现任意表演;
- 环境一致性:背景、光照、镜头运动保持自然;
- 支持长时序生成:通过时序潜码机制突破固定帧数限制。
这使模型在虚拟人、影视、游戏动画中具备巨大潜力。
关键创新点
1. 身体与表情解耦控制
通过骨骼与表情两路信号的独立注入,实现肢体与表情的双重控制。
2. 时序潜码与长视频生成
引入 Temporal Latent 机制,支持迭代生成长视频片段,并保持帧间连续性。
3. Relighting LoRA 光照适配
通过环境光照匹配训练,让角色在替换场景中光影自然一致。
与前代方法及 SOTA 对比
- 统一框架:同时处理动作、表情与环境;
- 基于视频扩散模型:生成质量显著提升;
- 高泛化性:适应真人、动漫、游戏角色;
- 开源易用:在消费级 GPU 上即可运行,支持 HuggingFace 与 ModelScope。
综合指标显示,WAN 2.2-Animate 已达到开源最先进水平(SOTA),接近商用级动画软件质量。
训练数据与策略
数据构建
- 大规模人像视频,自监督提取骨骼、掩膜、文本描述;
- 使用 Segment Anything (SAM2) 分割角色与背景;
- 自动生成掩码与标签,降低人工成本。
五阶段训练流程
- 身体控制训练:学习骨骼驱动;
- 面部控制训练:学习表情复刻;
- 联合控制训练:融合两类信号;
- 联合模式训练:加入 Replacement 模式;
- Relighting LoRA 微调:训练光照调整模块。
这种多阶段递进策略使模型在动作、表情与光照上均达到高度协调与真实性。
总结
WAN 2.2-Animate 的成功源于:
- 统一架构设计:实现动作、表情、环境一体化控制;
- 渐进训练策略:通过自监督与模块化训练提升效果;
- 开源可用性:推动高保真角色动画的普及。
这一模型的开源为数字人、影视、游戏制作等领域带来革命性机遇。

