
Quick Review: QUIK: Towards End-to-end 4-Bit Inference on Generative Large Language Models
作者:XD / 发表: 2023年12月7日 00:06 / 更新: 2023年12月7日 00:06 / 科研学习 / 阅读量:2200
QUIK: Towards End-to-End 4-Bit Inference on Generative Large Language Models
- Paper: QUIK on arXiv
- Code: QUIK on GitHub
- Organization: ETH Zurich
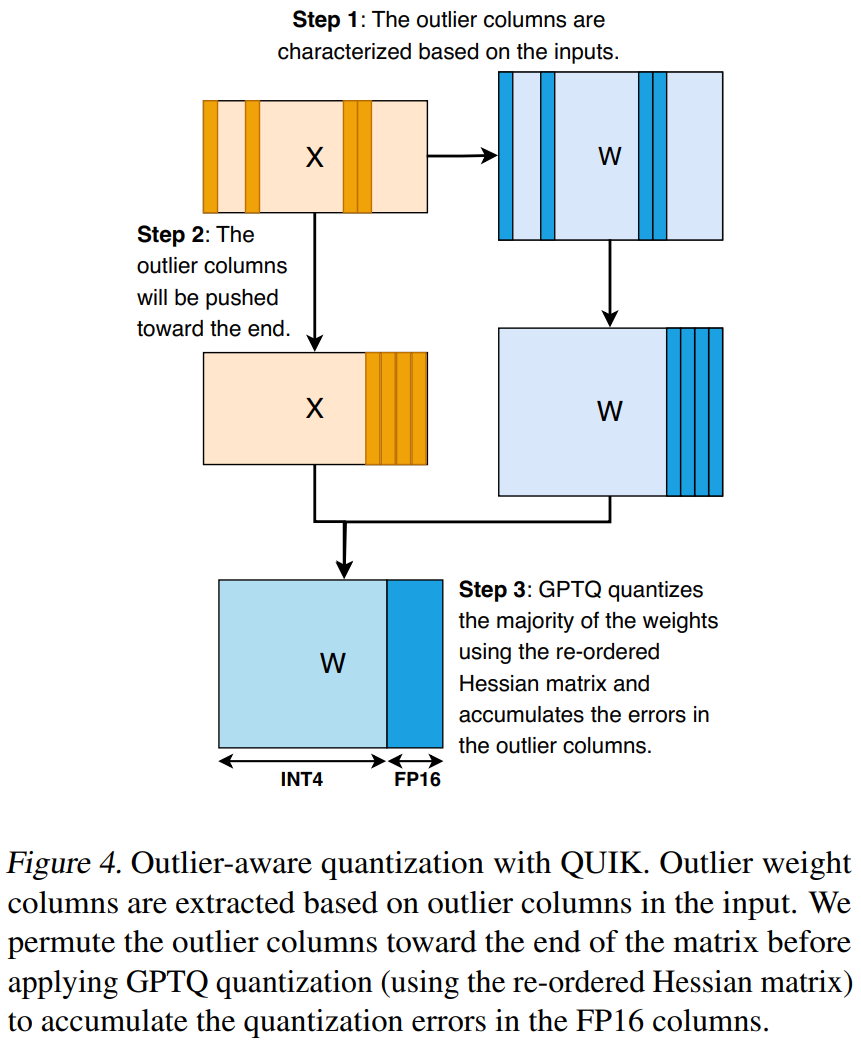
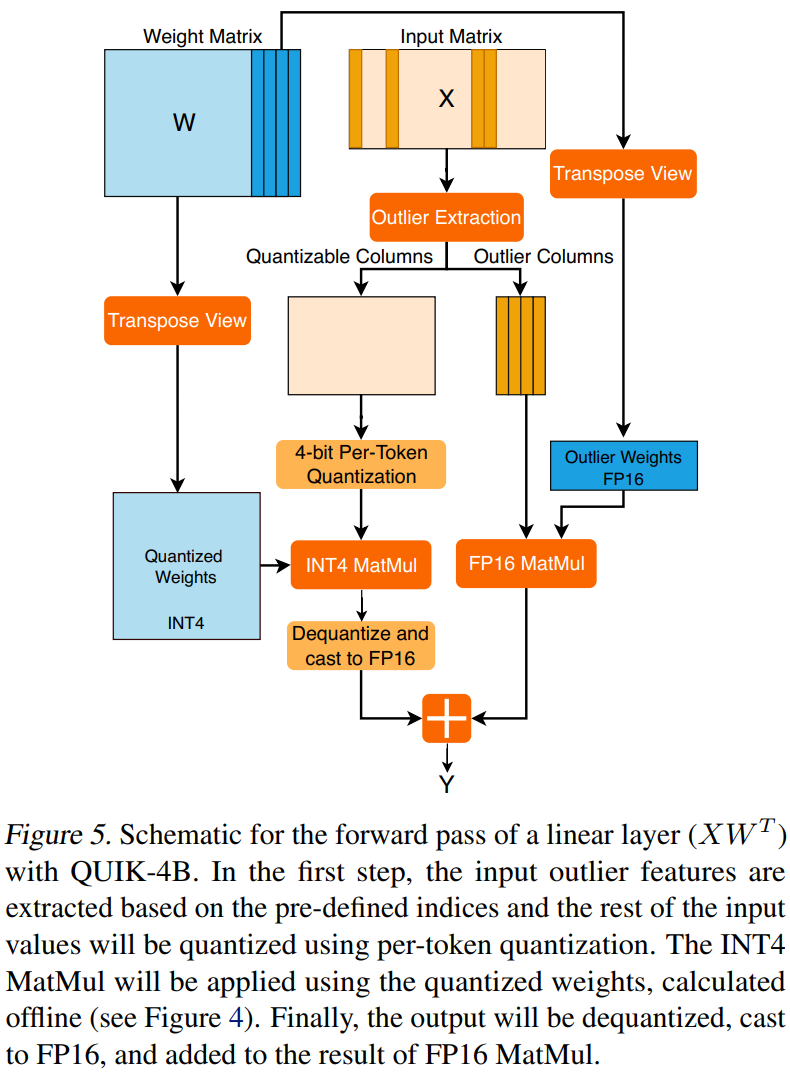
Key Features:
- Int4 Calculation: Implements 4-bit integer (Int4) calculations to significantly enhance inference speed.
- Reduced KV Cache Memory: Utilizes this technique mayb decrease Key-Value (KV) cache memory requirements, enabling more efficient processing of large language models.

相关标签
