
Review: H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
作者:XD / 发表: 2023年11月21日 02:22 / 更新: 2023年12月6日 23:53 / 科研学习 / 阅读量:3054
Title: [NeurIPS'23] H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models.
Rating: Average, Not Recommended
Paper:H2O Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
Code:https://github.com/FMInference/H2O
Review:
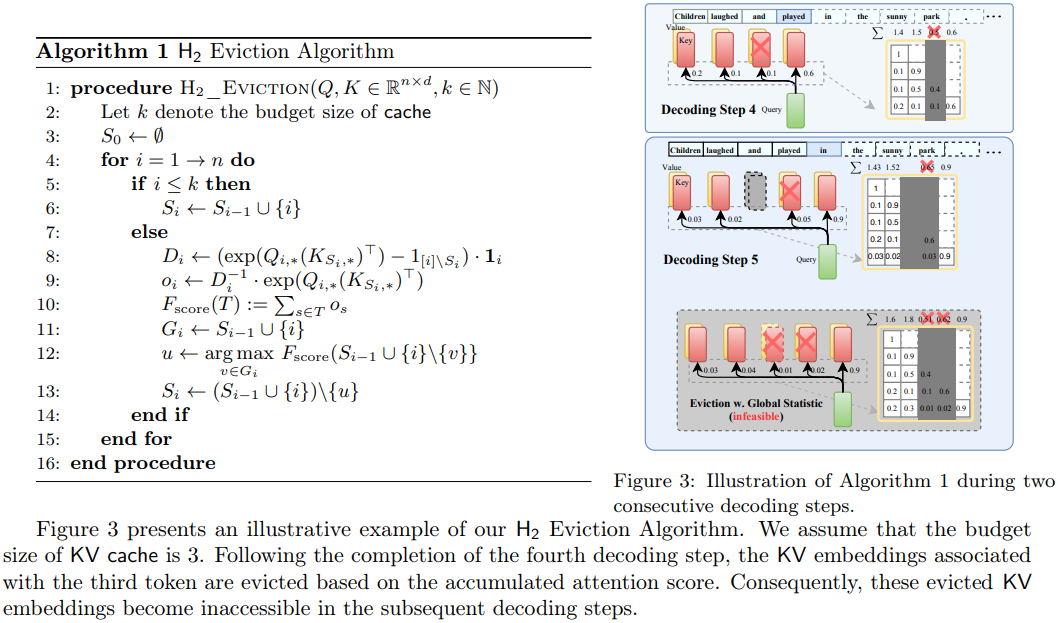
The paper introduces an approach to reduce KV cache in large language models by selecting the top k values as the main KV Cache for the following computing. However, the presentation of Algorithm 1 is complex and lacks clarity, for example, the element 'Gi' not being mentioned in the paper. This obscurity makes it difficult to understand the main idea. Further, the actual method, as revealed by the code, is disappointing, at least for LLAMA. It merely involves applying softmax to the QK matrix for updated scores and then selecting the top k indices for the mask update. This approach seems overly simplistic and does not match the expected sophistication of the proposed solution.
该论文提出了一种减少大型语言模型中KV缓存的方法,通过选择计算中的前k个数值作为主要KV缓存进行后续的计算。然而,算法1的呈现复杂且缺乏清晰度,比如元素'Gi'未提及,使得算法难以理解。进一步查看其代码,实际方法令人失望,至少对于LLAMA模型应用来讲。它只是对QK矩阵应用softmax得到更新的分数,然后选择前k个索引更新掩码。这种方法过于简单,并未达到预期的复杂性和提出的解决方案的深度。
modify_llama.py def local_heavy_hitter_mask
def local_heavy_hitter_mask(attn_weights, heavy_budget):
# 获取注意力权重的数据类型和序列长度
dtype_attn_weights = attn_weights.dtype
seq_length = attn_weights.shape[-1]
padding_length = 0
# 对注意力权重应用softmax函数以获得正规化的注意力分布
tmp_attn = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(dtype_attn_weights)
# 计算前heavy_budget个令牌的累积注意力分数
accumulated_attention_score = torch.sum(tmp_attn[:,:,padding_length:heavy_budget+padding_length,:], dim=-2) # (head, keys)
# 对超出预算的部分分数置零
accumulated_attention_score[:,:,heavy_budget+padding_length:] = 0
accumulated_attention_score[:,:,:padding_length] = 0
# 初始化一个与注意力权重形状相同的零掩码张量
mask_bottom = torch.zeros_like(attn_weights, dtype=torch.bool)
# 在掩码中标记重击者区域为True
mask_bottom[:,:, padding_length:heavy_budget+padding_length, padding_length:heavy_budget+padding_length] = True
# 遍历序列中的每个令牌
for token_index in range(heavy_budget+padding_length, seq_length):
# 计算当前令牌的softmax注意力权重
tmp_attn_index = nn.functional.softmax(attn_weights[:,:,token_index,:], dim=-1, dtype=torch.float32).to(dtype_attn_weights)
# 选择前heavy_budget-1个最高的累积注意力分数
_, tmp_topk_index = accumulated_attention_score.topk(k=heavy_budget-1, dim=-1)
# 创建当前令牌的零掩码张量
zeros_index = torch.zeros_like(tmp_attn_index, dtype=torch.bool)
# 更新当前令牌的掩码,标记最高分数的位置
mask_bottom_index = zeros_index.scatter(-1, tmp_topk_index, True) # (head, keys)
mask_bottom_index[:,:, token_index] = True
# 更新总掩码,将当前令牌的掩码信息添加进去
mask_bottom[:,:,token_index,:] = mask_bottom_index
# 更新累积注意力分数
accumulated_attention_score += tmp_attn_index
accumulated_attention_score = accumulated_attention_score * mask_bottom_index
# 返回计算得到的掩码
return mask_bottom

