
SAM 3:从 Prompt 到通用分割 — 一个技术/算法深度解析
作者:XD / 发表: 2025年11月30日 23:45 / 更新: 2025年11月30日 23:45 / 科研学习 / 阅读量:1792


一、什么是 SAM 3
- SAM 3 是 Meta 在 2025 年推出的新一代视觉基础模型,全称 “Segment Anything Model 3”。它是一种统一 (unified) 的基础视觉模型,能对图像 (image) 和视频 (video) 执行 检测 (detection)、分割 (segmentation) 和 追踪 (tracking)。(Meta AI)
- 与此前版本 (例如 SAM 2) 不同的是,SAM 3 大幅扩展了提示 (prompting) 机制 —— 不再仅依赖视觉提示 (如点 / 框 /已有 mask),而是加入 “概念提示 (concept prompts)”,即支持 文本短语 (text prompt) 和/或 图像示例 (image exemplar prompt)。这样,用户可以像 “英语 + 语义 + 视觉” 混合提示模型。(arXiv)
- 基于提示 (text 或 exemplar),SAM 3 会自动识别图像 / 视频中所有符合 “该概念 (concept)” 的实例 (所有 object instances),为它们生成 mask,并在 video 中保持一致的身份 ID — 也就是所谓的 Promptable Concept Segmentation (PCS)。(datature.io)
换句话说,SAM 3 不只是 “分割你点 / 框出来的一个物体”,而是 “分割图中所有符合你所说 / 给出的那个概念 (concept)” 的所有物体,实现 open-vocabulary 的通用分割 + 跟踪。
二、技术 / 算法创新 — 为什么 SAM 3 是“范式级”进化
✅ 1. Promptable Concept Segmentation (PCS):语义 + 视觉融合
传统分割 /实例分割模型,多数依赖一组预定义类别 (比如 “人 / 狗 / 车 / 桌子 / …”)。即使是 earlier SAM/ Mask-R-CNN/DETR 类模型,也属于 “类别 + 视觉提示 (point/box/mask)” 模型。
SAM 3 则引入 PCS:
- 开放词汇 (open-vocabulary):你可以用任意短语 (noun-phrase),例如
"yellow school bus","striped cat","red umbrella",模型尝试理解其语义 + 视觉定义。(datature.io) - 多模态提示 (text + exemplar + visual prompt 混合):如果你觉得文字描述不够明确,也可以给一个示例图 (image exemplar) —— 模型会把这个示例作为概念模板 (visual concept prototype),然后在目标图像/视频中找所有相似概念实例。(Ultralytics Docs)
这种机制将分割任务提升为 一个语义 + 视觉 + 概念级别 (concept-level) 的任务,大幅扩展了分割模型的通用性和灵活性。
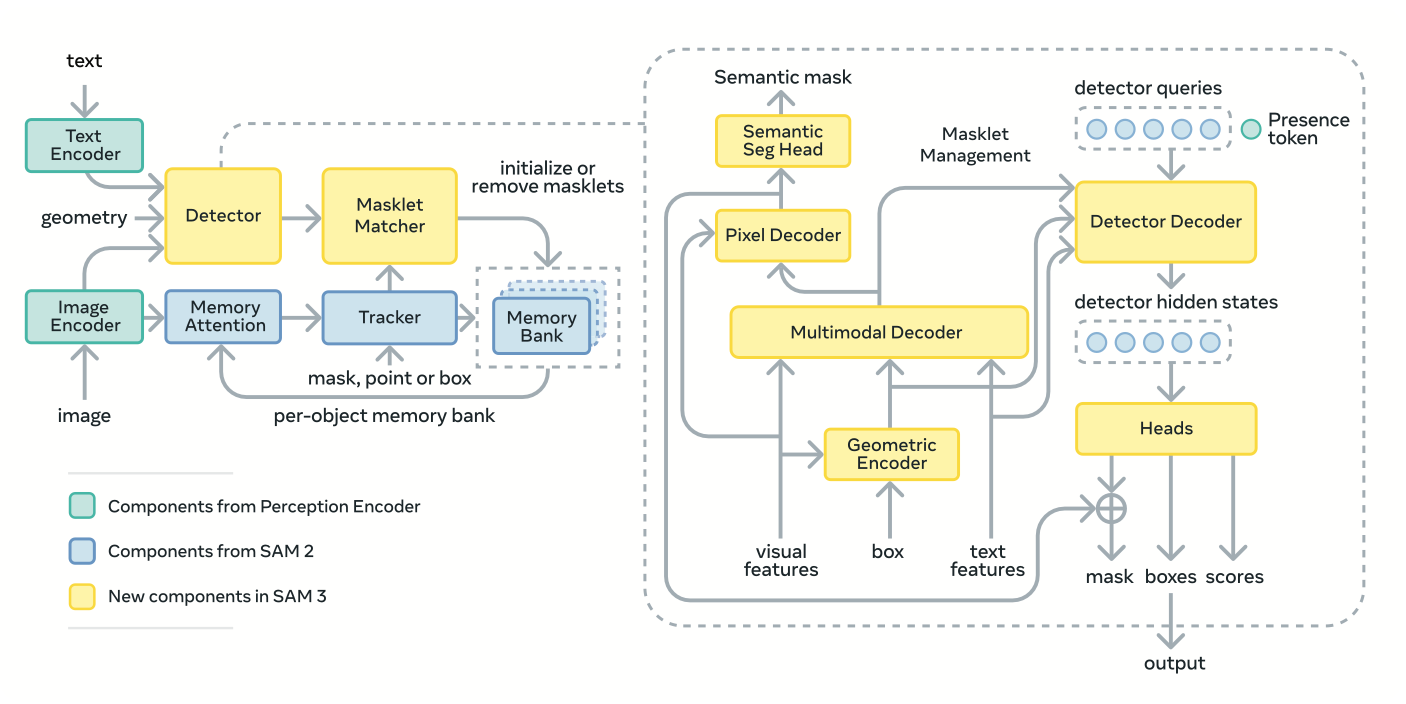
🧠 2. 统一架构设计:Detector + Tracker + Perception Encoder
SAM 3 的内部架构设计也是其技术亮点 — 它是一种 hybrid / unified 架构,将多个任务 (detection, segmentation, tracking) 合并在一个模型/pipeline 中。具体包括:(encord.com)
- Perception Encoder (PE):一个视觉–语言 backbone,用来编码图像 + prompt (text 或 exemplar 或视觉提示) —— 这些特征作为下游任务 (detection / segmentation / tracking) 的通用输入。(encord.com)
- DETR-style Detector:针对给出的 prompt (概念) 执行检测 (detection):也就是首先识别哪些区域 (boxes /候选 proposals) 可能属于该概念。(encord.com)
- Mask / Segmentation Head + “Presence Head”:在检测出候选后,对每个候选做 mask segmentation,将 object 精确地分割出来。“Presence head” 是 SAM 3 的一个新模块 —— 它在检测 (what is) 和定位 (where is) 之间解耦 (decouple recognition from localization),即先确定“这个概念是否存在 / 有多少实例 (how many)”,再对每个实例做分割。(Medium)
- Temporal Tracking / Memory Module (for Video):对于视频输入 (multi-frame),SAM 3 会结合类似其前代 (SAM 2) 的 transformer-based tracker + memory 模块,实现跨帧对象的 ID 保持 + 跟踪 (tracking),确保同一对象在视频不同帧中能保持一致身份。(encord.com)
这样的设计使得 SAM 3 成为一个 “从 prompt 到分割/跟踪 (end-to-end)” 的统一系统 — 用户只需要给概念提示 (text / exemplar / visual prompt),就能得到所有符合该概念对象的 segmentation masks (以及在 video 中的 tracking);不再需要为 detection、segmentation、tracking 分别调用不同模型 / pipeline。
🚀 3. 大规模数据引擎 + 通用训练 (open-vocabulary + zero-shot)
要让模型真正理解任意自然语言 + 视觉概念,并且泛化到 long-tail (长尾) 对象,关键在于数据。SAM 3 的作者设计了一个大规模、半自动化的数据引擎 (data engine),结合 AI + 人类标注 (human+AI loop),为 数百万 (millions) 的自然语言概念 (noun phrases) + 示例图 / mask 生成训练数据。这样,模型在训练时就能见到多样、丰富、开源词汇 + 多样视觉表现形式,从而具备了 zero-shot / few-shot 推理能力。(ithome.com.tw)
根据官方论文,SAM 3 的 PCS (Promptable Concept Segmentation) 能够在没有针对性微调 (fine-tune) 的情况下,直接对新的、未见过的概念做 segmentation —— 这是 open-vocabulary / zero-shot 的重要体现。(arXiv)
三、模型能力 & 性能提升
SAM 3 相比前代 /其他模型,有如下显著优势 /能力:
- 📌 Open-vocabulary segmentation + concept-level generalization:不再限于预设类别,而是对任意自然语言描述 /示例图像 (visual exemplar) 的概念进行分割。(GitHub)
- 🔄 统一 detection + segmentation + tracking pipeline:支持图像 & 视频输入,一体化处理 detection 、mask segmentation 与跨帧 tracking。(Meta AI)
- ⚡ 高效率 & 实用性:虽然功能丰富,但设计考虑到工程落地 — 可用于生产系统 / 实时 /批量 /交互式分割任务。(InfoQ)
- 🌐 Zero-shot / Few-shot 能力 + 强泛化性:对未见过的新概念、新视觉形态具有较好适应能力,减少了为每个新类 / 新场景重新训练 /微调的开销。(arXiv)
四、局限与挑战 (当前与未来)
当然,SAM 3 虽然强大,但从算法 /应用角度来看,也存在一些局限 /挑战:
- ⚠️ 概念提示 (prompt) 的语义 / 表述质量依赖性:如果 prompt 太模糊 (e.g. “美丽的鸟” / “奇怪的物体”),可能导致分割结果不稳定 —— 模型对于模棱两可 /歧义概念的不确定性还需靠交互 / 多提示 /人工校正。
- 🧑💻 资源消耗:统一模型 + detection + segmentation + tracking + open-vocabulary 带来了复杂性与计算 /内存开销,对于实时 / 轻量 /设备部署 (edge / mobile /嵌入式) 仍然是挑战。已有研究 (比如 EfficientSAM3) 表示,需要通过蒸馏 /适配 (distillation / adapter) 才可能适应资源受限场景。(arXiv)
- 🎯 长尾 / 极端 /复杂概念 /场景:虽然开放词汇 + 大规模数据训练提升了泛化,但对于非常罕见 / 高度复杂 / 抽象 /混合 (mixed) 概念 (例如 “穿蓝绿条纹衣服、头戴黄色帽子、拿红包的人”),模型是否能准确分割和区分,仍可能存在瓶颈。
五、对研究 /工程 /应用 的意义
从算法与工程角度看,SAM 3 的出现具有以下重要意义:
- 🧱 视觉基础模型 (Vision Foundation Model) 的新范式:类似语言模型 (Large Language Model, LLM) 在 NLP 的地位,SAM 3 可能成为视觉 /多模态领域的基础模型 — 不再针对于固定任务 (分类 / detection / segmentation),而是支持 任意视觉概念 + open-vocabulary + 多模态提示 的通用任务。这将极大简化 downstream pipelines,让研究者 /工程师更专注于任务逻辑,而非数据 / 模型训练。
- 🔄 数据标注 /自动标注流程变革:借助 open-vocabulary segmentation + zero-shot 能力,可以大幅减少对人工标注 /类别定义 /数据收集的依赖。对于大规模数据集构建、多样化场景标注、多模态数据集构建 (image / video /概念 /异常) 有巨大帮助。
- 📦 跨任务 /跨模态 /跨领域适用:从图像 / 视频到 (甚至将来) 3D,从简单对象分割到复杂概念 /混合任务 — 对机器人、自动驾驶、AR/VR、媒体编辑、内容生成 (图像/视频/3D) 等领域都有潜在价值。
六、如何开始使用 / 实验 SAM 3
如果你是研究者 /工程师 /开发者,可以这样开始尝试 SAM 3:
- 克隆其官方仓库:facebookresearch/sam3 。(GitHub)
- 准备 prompt:可以是文字 (English noun-phrase) 或者示例图像 (image exemplar) + 可选视觉提示 (box / mask / point)
- 输入图像或视频:模型将输出 segmentation masks + (if video) tracking IDs
- (可选) 对输出进行后处理 / 集成到下游系统 (如数据标注、视频编辑、物体检测 /识别 /分析)
如果需要资源友好 /轻量 /部署友好的版本,也可以关注社区提供的压缩 /蒸馏 /适配版本 (例如 EfficientSAM3、SAM3-Adapter 等) 来适应边缘设备 /实际工程环境。(arXiv)
七、小结
SAM 3 不仅仅是一次 “模型升级 /性能提升”,而是一场 计算机视觉领域范式 (paradigm) 的变革 —— 从传统 “类别 + 视觉提示” 的分割 /检测 /识别系统,跃迁为 “语言 /视觉 /概念 + 多模态提示 + 分割/检测/追踪 + open-vocabulary + zero-shot” 的通用视觉基础模型。
对于研究者、工程师与实际应用系统来说,它降低了 “定义类别 / 收集数据 / 标注 / 训练 / 微调 / 集成” 的门槛,让视觉理解与处理变得更灵活、更通用、更自动化。
当然,也正因为其复杂与通用,SAM 3 的资源要求、Prompt 质量、应用场景适应性等,也值得我们深入研究与评估。未来随着社区、研究者的贡献 (轻量化、适配、优化、下游任务集成),它可能成为视觉/多模态系统中的基础组件,就像语言模型在 NLP 领域中的地位一样。
如果你同意,我可以继续帮你 生成一个包含 Python 推理 (inference) 示例 + benchmark 性能测试脚本 的完整 技术入门 + 实验笔记 blog 模板(方便你直接跑起来 SAM 3 并测试效果)。你想要我帮你生成吗?

